

На заре машинного обучения большинство решений выглядели очень странно, обособленно и необычно. Сегодня множество ML алгоритмов уже выстраиваются в привычный для программиста набор фреймворков и тулкитов, с которыми можно работать, не вдаваясь в детали их реализации.
К слову, я противник такого поверхностного подхода, но для своих коллег хотел бы показать, что эта отрасль движется семимильными шагами и нет ничего сложного, чтобы применять ее наработки в продакшен проектах.
Для примера я покажу, как можно помочь пользователю найти нужный видеоматериал среди сотен других в нашем сервисе документооборота.
В моем проекте пользователи создают и обмениваются сотнями различных материалов: текстом, картинками, видеороликами, статьями, документами в различных форматах.
Поиск по документам представляется достаточно просто. Но что делать с поиском по мультимедиа контенту? Для полноценного сервиса пользователя надо обязать заполнить описание, дать название видеоролику или картинке, не помешает несколько тегов. К сожалению, далеко не все хотят тратить время на подобные улучшения контента. Обычно пользователь загружает ссылку на youtube, сообщает что это новое видео и нажимает сохранить. Что же делать сервису с таким “серым” контентом. Первая идея — спросить у YouTube? Но YouTube тоже наполняют пользователи (часто это один и тот же пользователь). Часто видеоматериал может быть и не с Youtube сервиса.
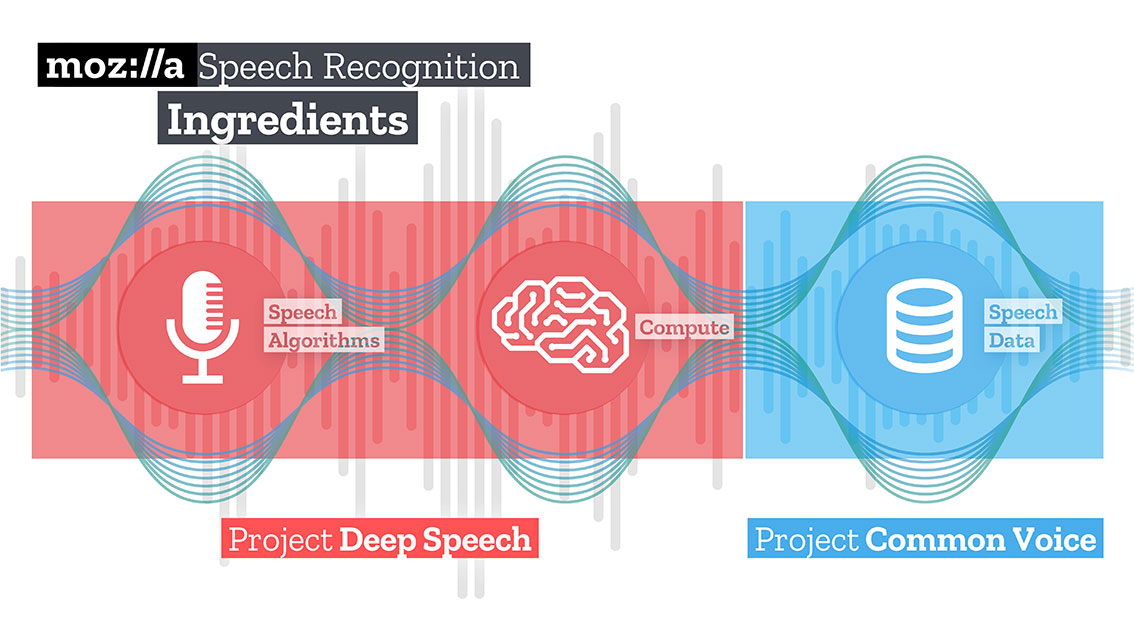
Так мне пришла идея научить наш сервис “слушать” видеоролик и самостоятельно “понимать”, о чем он.
Читать дальше →
О чем говорит YouTube
Source: geektimes