

Всех с пятницей! В своём прошлом посте про хеш-стеганографию я предложил иной подход в стеганографии — не вкраплять никакой информации в контейнер, а просто упорядочивать контейнеры в нужном порядке и тем самым передавать скрытую информацию. Два дня назад romabibi опубликовал proof of consept для хеш-стеганографии в соц.сети вКонтакте.
Однако в использовании картинок как контейнеров есть важный изьян. Цитирую коммент alekseev_ap:
Всё это очень интересно, но КПД такой системы чрезвычайно низкий. Сколько надо отправить десятков (а то и сотен) килобайт чтобы передать строку из нескольких слов?!
Действительно, если изображение весит условно 0.5 — 2 Мбайт, а на каждое изображение мы передаем от 1 до 3 нибллов, то получаемая скорость очень мала: от 0.5 до 6 B/MB
Поэтому для практического применения нужно найти такой контейнер, который обладал бы следующими свойствами:
- был бы очень мал;
- при большом количестве контейнеров, стоящие друг за другом; не вызывал бы «подозрений»;
- при смене порядка контейнеров, они бы не вызывали «подозрение».
Итак, капитан-очевидность решение: необходимо осуществлять хеш-стеганографию в больших датасетах. Одна строка — один ниббл (полубайт).
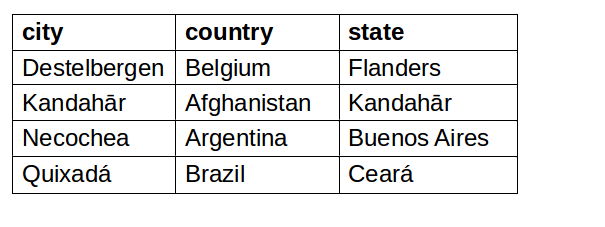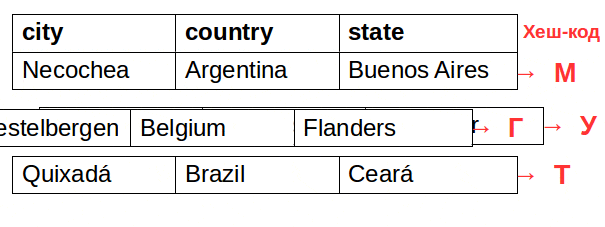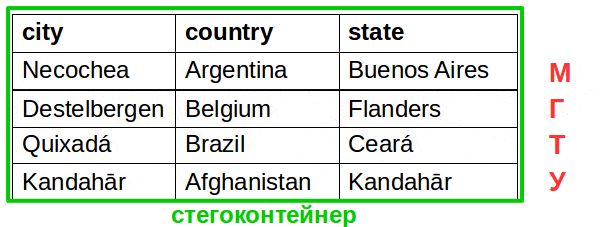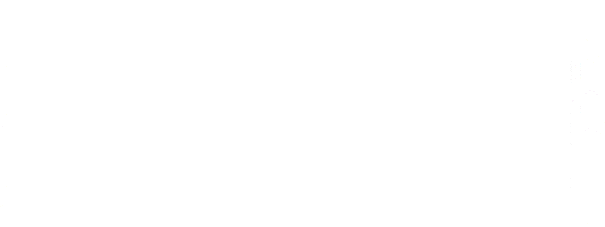
Дальше читать
Хеш-стеганография в dataset-ах. На этот раз быстрая
Source: habrahabr